Simplification always creates compression of the information. Any compression leads to the loss of the „devil is in the detail“ layers. I love to simplify, but when we simplify, we must accept the tradeoff of losing the „devil is in the detail“ layer.
static programming language = square pegs in a round hole

Certain things simply do not match. And just like the saying „square pegs in a round hole„, in static programming language you cannot dynamically change the variable type as you go. For example, C++ is a statically-typed language, which means that the type of a variable is known at compile time, and once you’ve declared a variable of a certain type, you cannot change its type during its lifetime.
For instance, languages like Python are dynamically typed, meaning that the type of a variable can change at runtime. Statically typed is determined at the compile time.
WHY Is It Important?
- Just being aware of the difference brings clarity to the way you are going to design your code.
NOWwhat?
- You have just learned a dynamic-static typing micro skill.
Unravel, don’t tangle.
game theory = howto’s on strategic decision making with informational constraints
In Poker there is a saying, „Play a player, not the cards“. In the age of high compute throughput and almost infinite data access and data storage, one has to wonder if you have any advantage in playing the financial markets. And not just you, but also any professional advisor or money manager. What is the advantage they have if everyone has the access to same informational and computing resources?
One discipline that has been here for millennia is game theory. Game theory is trying to explain the story of participants and the way they make their calculated decisions. Rather than studying how you can count the cards, you study how to read the people (making decisions) who deal with the cards they have not knowing what cards they have (informational constraints).
linear regression = finding the right weights to balance a scale
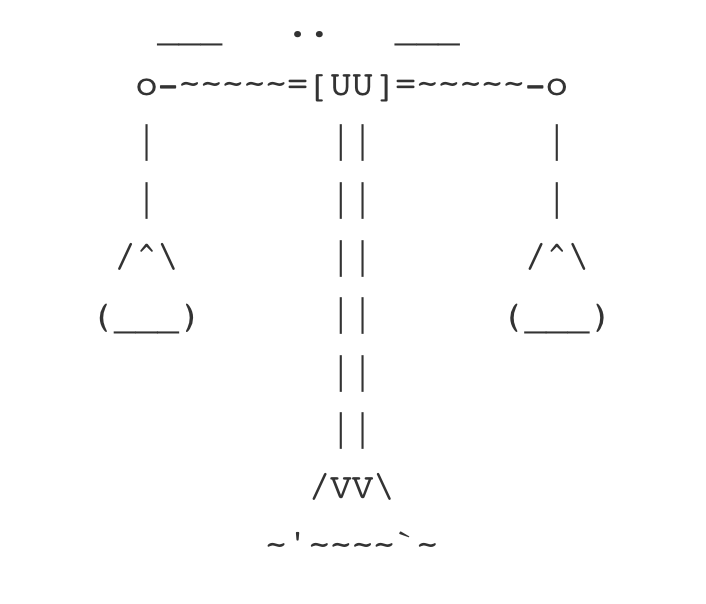
Visualize the data points as weights on one side of a balancing scale. Your task is to find the right combination of weights (coefficients) for the objects on the other side to balance the scale perfectly. Linear regression involves adjusting the weights until the scale is in equilibrium, which means the difference between the two sides is minimized. The weights‘ values and positions correspond to the coefficients of the linear equation, and once the scale is balanced, you can use this equation to make predictions for new weights.
Unravel, don’t tangle.
bytecode = the MEAT between human and machine code
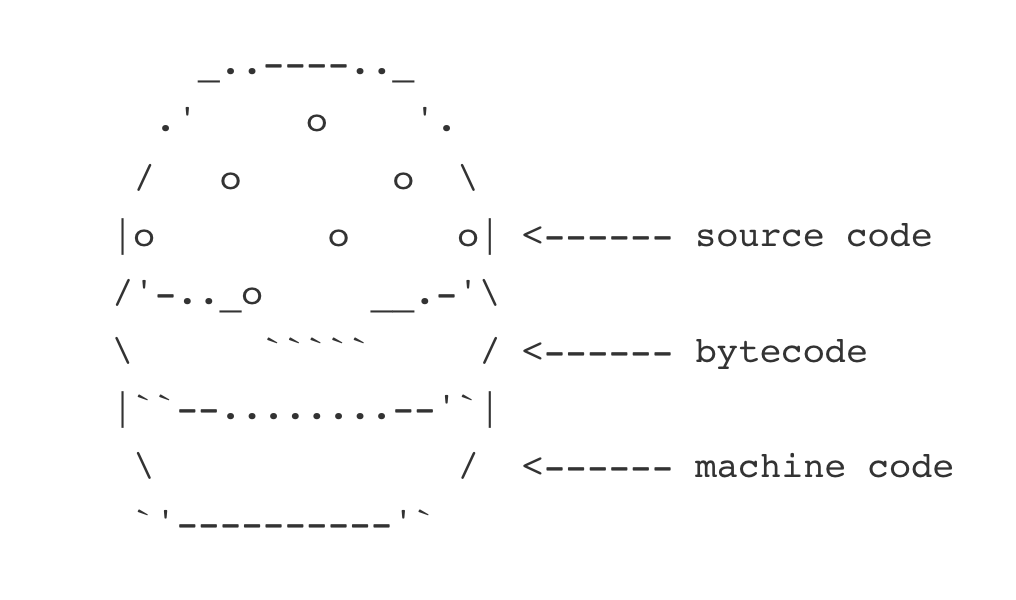
Unravel, don’t tangle. #Python
Seek To Understand > Seek To Argue
Explore all opinions with a child like curiosity. Especially opinions that heavily contradict yours. Seek to understand, not to argue.
Unravel, don’t tangle.
vector embeddings = your moody playlist
Imagine you have playlists for different moods – happy, sad, energetic, etc. The songs in each playlist are different, but they all share a common theme or mood.
Similarly, words that share similar context or meaning will be close together in the embedding space, just like songs sharing the same mood are grouped into the same playlist.
Unravel, don’t tangle.
perfect flavor = gradient descent
When cooking a new dish, you add a pinch of seasoning, taste it, and adjust accordingly. If it’s too bland, you add more; if it’s too salty, you reduce the seasoning. This process continues iteratively until you achieve the perfect flavor.
Unravel, don’t tangle.
context length !=29

The context window (context length) of a LLM is the length of the longest sequence of tokens that a LLM can use to generate a token. If a LLM is to generate a token over a sequence longer than the context window, it would have to either truncate the sequence down to the context window, or use certain algorithmic modifications.
Ok, so the fancy term „context length“ is nothing else than a token count. And token count is nothing else than words count. Not quite. This is what the internet has to say about that:
A general rule of thumb is that one token is roughly equivalent to 4 characters of text in common English text. This means that 100 tokens are approximately equal to 75 words.
So if we take our two sentences and throw them into the OpenAI Tokenizer, this is what we get:

So is the internet correct about 4 characters approximation? Let’s ask chatGPT4:

Not quite. The approximation can actually confuse rather than clarify. So rather than using the approximation of 4, just remember that short words, spaces, and punctuations often end up being represented by single tokens.
Unravel, don’t tangle